Abschlussbericht zum Projekt
"Ausbau und Erweiterung eines Open-Source-Tools
zur Nachkorrektur historischer OCR-erfasster Texte"
der CLARIN-D Facharbeitsgruppe 4-3 “Klassische Philologie”
Antragssteller
Prof. Dr. Klaus U. Schulz
Ludwig-Maximilians-Universität München
Centrum für Informations- und Sprachverarbeitung
Oettingenstraße 67
D-80538 München
Kontakt: schulz@cis.uni-muenchen.de
Telefon: +49 (0) 89 / 2180 - 9700
Fax: +49 (0) 89 / 2180 - 9701
Ausführende Institution
Name: Centrum für Informations- und Sprachverarbeitung (CIS)
Institution: Ludwig-Maximilians-Universität München
Vertragsnummer: CLARIN-DE-FAG4-KP3
Kurzbezeichnung: „Open-Source Tool zur OCR-Nachkorrektur“
Projektzeitraum
01.04.2015 – 31.03.2016
Bearbeiter
Florian Fink (50%), Dr. Uwe Springmann (25%)
Kurzdarstellung
Die Aufgabenstellung bestand darin, eine Software (PoCoTo = Post Corrrection Tool) zur maschinell unterstützten, interaktiven Nachkorrektur von OCR-erfassten historischen Texten, die aus einem Vorgänger-EU-Projekt (IMPACT, 2008-2012) als Proof-of-Concept vorlag, zu einer stabilen und fehlerfreien, breit einsetzbaren und als Open-Source nachnutzbaren Anwendung zu entwickeln. Gleichzeitig sollten Erweiterungen in Bezug auf In- und Outputformate (Text, ABBYY XML, hOCR, TEI), verwendbare OCR-Engines (ABBYY, Tesseract, OCRopus) sowie die Einbeziehung weiterer Sprachen (im Sinne einer lexikalischen Unterstützung der Berechnung von sprachabhängigen Fehlerprofilen für OCR-erfasste Dokumente) vorgenommen werden. Teil des Antrags war auch die Bemühung um die Schaffung einer Community, die an einem solchen Werkzeug Interesse hat und aktiv über Nutzung und Feedback Einfluss auf die Weiterentwicklung nimmt bzw. sich an ihr beteiligt.
Der Auftrag wurde als FE-Auftrag mit dem Max-Planck-Institut für Psycholinguistik in Nimwegen als Auftraggeber vom Centrum für Informations- und Sprachverarbeitung der LMU München abgewickelt (Auftragsnummer CLARIN-DE-FAG4-KP3). Bearbeiter waren Florian Fink (50%) und Dr. Uwe Springmann (25%).
Der Stand vor Beginn des Projekts in Bezug auf die dem Nachkorrekturtool zugrundeliegende, am CIS entwickelte Profilertechnologie ist dokumentiert in:
Mihov, Stoyan, and Klaus U. Schulz. 2004. Fast Approximate Search in Large Dictionaries. Computational Linguistics 30 (4). MIT Press: 451–77.
Reffle, Ulrich. 2011. Algorithmen und Methoden zur dokumentenspezifischen Analyse historischer und OCR-erfasster Texte. Verlag Dr. Hut.
Reffle, Ulrich, and Christoph Ringlstetter. 2013. Unsupervised Profiling of OCRed Historical Documents. Pattern Recognition 46 (5): 1346–57. doi:http://dx.doi.org/10.1016/j.patcog.2012.10.002.
Schulz, Klaus U., and Stoyan Mihov. 2002. Fast String Correction with Levenshtein Automata. International Journal on Document Analysis and Recognition 5 (1). Springer: 67–85
Das Nachkorrekturwerkzeug PoCoto selbst wurde beschrieben in:
Vobl, Thorsten, Annettee Gotscharek, Uli Reffle, Christoph Ringlstetter, and Klaus U. Schulz. 2014. PoCoTo - an Open Source System for Efficient Interactive Postcorrection of OCRed Historical Texts. In Proceedings of the First International Conference on Digital Access to Textual Cultural Heritage, 57–61. DATeCH ’14. New York, NY, USA: ACM. doi:10.1145/2595188.2595197.
Eingehende Darstellung
Erzielte Ergebnisse
Die ursprünglichen Ziele, PoCoTo zu einer stabil verwendbaren Anwendung zu entwickeln, wurde im Projektverlauf vollständig erreicht. Intensive Tests, die teilweise im Rahmen von Bachelor- und Magisterarbeiten am CIS insbesondere für die Behandlung lateinischer und spanischer OCR-erfasster historischer Texte durchgeführt wurden, führten nicht nur zur Behebung einer Vielzahl entdeckter Fehler, sondern auch zu einigen sinnvollen Weiterentwicklungen wie der Möglichkeit, ein einmal erzeugtes Fehlerprofil lokal in PoCoTo zu importieren bzw. der generellen Komprimierung der teilweise riesigen textbasierten Profildateien vor der Versendung über das Netzwerk vom Profiler-Server zum Anwender. Die Profildateien enthalten die Angabe von Korrekturkandidaten für jedes einzelne OCR-Token mit zusätzlichen Informationen, so dass bei einigen hundert Seiten erkannter Text Dateigrößen im GB-Bereich resultieren können.
Um die speziell in Aussicht gestellte Anbindung an die für die OCR historischer Texte interessanten, auf historische Typographie trainierbaren Engines Tesseract und OCRopus herzustellen und die bisherige einseitige Abhängigkeit von der proprietären ABBYY-Finereader-Engine zu überwinden, wurde PoCoTo so angepasst, dass jetzt auch die hOCR-Formate wortbasiert von beiden Engines in PoCoTo übernommen werden können. Das war vorher nicht möglich, weil Tesseract hOCR-Tokens mit anhängenden Satzzeichen lieferte, OCRopus lediglich ganze Zeilen. Hier hat uns die zwischenzeitlich erfolgte Community-basierte Weiterentwicklung von OCRopus auf github bzw. die Umstellung der Tokenisierung auf eine PoCoTo-interne Logik zum Ziel gebracht. Damit sind jetzt insgesamt drei verschiedene OCR-Engines (ABBYY, Tesseract, OCRopus) verfügbar, die von PoCoTo nachkorrigierbaren OCR-Output liefern.
Zusätzlich ist es möglich, die korrigierten OCR-Ergebnisse als TEI-Dokument mit Seiten-, Absatz- und Zeilenauszeichnung zu exportieren. Bei Vorliegen der Bilddatei kann sogar eine in TEI ausgezeichnete fehlerbehaftete OCR in PoCoTo importiert werden und eine (erneut auf dem Bild vorzunehmende) OCR nach der Korrektur in dieselbe TEI-Struktur zurückgespeichert werden. Falls die ursprüngliche TEI, etwa nach dem von Ben Kiessling ausgearbeiteten Vorschlag unter Verwendung der Auszeichnungslabels für Faxe (Kiessling TEI for OCR), bereits Bildkoordinaten enthält, könnte man sich in einer Weiterenwicklung diese erneute OCR sparen und direkt das im TEI vorliegende OCR-Resultat nachkorrigieren.
Die Entwicklung einer Nutzergemeinde verlief wegen des ausgesprochen positiven Zuspruchs zu unseren beiden Workshops (14./15. September 2015: 28 Teilnehmer aus 17 nationalen und internationen Institutionen; 29. Januar 2016: Entwicklerworkshop mit 4 externen Teilnehmern) sehr erfreulich. Über eine Mailingliste für Interessierte findet ein Informationsaustausch statt und die Kooperation mit externen Entwicklern ist durch die Verlagerung der gesamten Entwicklung auf github erheblich erleichtert. Sämtliche Quellen sowohl der Software als auch der für den Workshop erzeugten Unterlagen (Präsentationen, Tutorials, Daten, Handbücher im Markdown-Format) sind dort unter einer quelloffenen Lizenz (Apache bzw. CC-BY-SA-NC) verfügbar. Zusätzlich stehen die Workshop-Dateien (Präsentationen) und die Handbücher zum Profiler (19 Seiten) und zu PoCoTo (33 Seiten) als markdown- und pdf-Versionen zur Verfügung.
Um PoCoTo erfolgreich auch auf neue Sprache anzupassen und interessierten Institutionen die Möglichkeit zu bieten, einen eigenen Profilerserver zu betreiben, stellte es sich als notwendig heraus, auch den Code des als Webservice ausgelegten Profilerservers erheblich anzupassen. Obwohl diese Arbeiten im ursprünglichen Antrag weder vorhergesehen noch budgetiert waren, ist es durch den Einsatz von Herrn Fink gelungen, auch diese Arbeiten innerhalb der Bearbeitungszeit vollständig abzuschließen. Alle notwendige Software wurde an das CLARIN-Zentrum in Leipzig übergeben, so dass Interessierte sowohl auf den dort einzurichtenden Profiler-Service zugreifen können und sich auch alternativ einen eigenen Service inhouse einrichten können, um unnötig hohen Netzverkehr zu vermeiden.
Die Einrichtung neuer Sprachprofile wird im Profilerhandbuch ausführlich beschrieben. An dieser Stelle tritt das leidige Problem der Verfügbarkeit freier Lexikaressourcen (sowohl moderner als auch historischer Vollformenlexika) auf, welches die gesamte Entwicklung computerlinguistischer Anwendungen negativ beeinflusst. Um hier ein Zeichen gegen eine hoffentlich zunehmend obsolet werdende, auf kurzfristige wirtschaftliche Vermarktbarkeit schielende Enteignung öffentlicher Güter zugunsten privater Interessen (und zu Ungunsten der weiteren Forschung, die in der Folge erheblich größere wirtschaftliche Potentiale freizusetzen helfen könnte) zu setzen, gehen wir mit gutem Beispiel voran und veröffentlichen die von uns erstellten quellfreien lexikalischen Ressourcen zu Latein und historischem Deutsch auf Github. Zusätzlich sind unter dem Repository auch aus Perseus erzeugte freie altgriechische Sprachressourcen für unsere Profilertechnologie verfügbar. Einige moderne Baseline-Lexika kann man sich zumindest über vorhandene Spellcheck-Lexika aus z.B. LibreOffice erzeugen (das Verfahren wird im Profiler-Handbuch beschrieben), und weitere historische Lexika sind (auf Anfrage) über das IMPACT Center of Competence erhältlich.
Es sind nunmehr sowohl der Profiler-Webservice wie auch PoCoTo in der Lage, OCR-erfasste historische Dokumente nicht nur für Deutsch (bei Vorliegen entsprechender lexikalischer Ressourcen auch für andere "moderne" europäische Sprachen) und Lateinisch, sondern auch für Altgriechisch zu verarbeiten. Die diesbezüglichen Arbeiten und Ergebnisse gehen insofern deutlich über den Projektplan hinaus, als dass weder die Verarbeitbarkeit altgriechischer Dokumente noch die hierfür notwendigen umfangreichen Anpassungen des Web-Services vorgesehen waren.
Um einen Eindruck vom erreichten Stand der Software zu geben, fügen wir hier ein Bild von PoCoTo im Einsatz bei der Korrektur des ersten Bandes der Septuaginta (griechische Übersetzung es Alten Testaments) von Swete (1901) bei. In der linken Spalte erkennt man die großen Fehlerserien, die sich bei der Fehl-Erkennung von Diakritika ergeben haben. Die gezeigte Tokenkonkordanz im oberen Bild zeigt die 501 Mitglieder der berechneten Fehlerserie (vermutet richtig --> falsch) ἀ --> ά, d.h. bei der ein Alpha mit Akut (ά) anstelle eines Alphas mit Spiritus lenis (ἀ) von der OCR erkannt wurde. Gleichzeitig wird der (in den allermeisten Fällen korrekte) Korrekurvorschlag angegeben, so dass man durch "Select all", schnelle Durchsicht mit Herausnahme der unkorrekten Vorschläge und "Correct" die ganze über das Buch verstreute Fehlerserie innerhalb von Sekunden beheben kann. Das Vorgehen wird im Handbuch in allen Einzelheiten beschrieben.
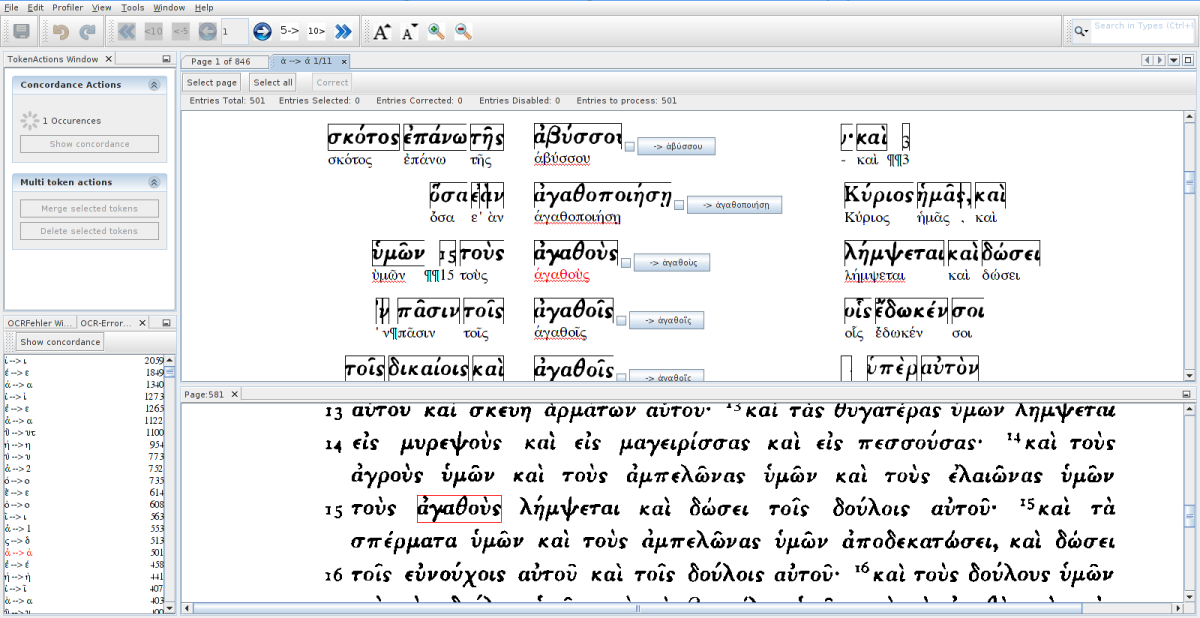
PoCoTo bei der Korrektur eines altgriechischen Textes
Voraussichtlicher Nutzen / Verwertbarkeit der Ergebnisse
Die in der Vergangenheit im Rahmen von z.B. VD16, VD17 und VD18 erzeugten umfangreichen Mengen von Scans von Buchseiten harren alle noch einer Transformation in elektronisch weiterverarbeitbaren Text, um ihr Anwendungspotential zu erschließen. Da in großem Rahmen aus Kosten- und Zeitgründen nur maschinelle Verfahren in Frage kommen, stellt die Art der Verfügbarkeit einer Nachkorrekturmöglichkeit einen zentralen Baustein dar, der die erreichbare Qualität der Texte und damit letztendlich ihren Wert für weitergehende wissenschaftliche Nutzungsmöglichkeiten maßgeblich mitbestimmt.
Das Interesse an unseren Ergebnissen zeigt sich nicht nur am lebhaften Zuspruch zu unseren Workshops und den daraus entstandenen Kontakten. Die erzielten Ergebnisse sind auch unmittelbar relevant in Bezug auf die Koordinierung zur Ausschreibung einer massentauglichen OCR historischer Buchbestände, für die die Voraussetzungen inzwischen vorliegen. Bereits jetzt kann sich der interessierte Nutzer mit frei verfügbaren Werkzeugen und ihn interessierenden Buchscans einen Text in einem Bruchteil des Aufwands verglichen mit einer manuellen Transkription verschaffen, indem er ihn in einer im Workshop ausführlich dargestellten Reihe von Schritten vorverarbeitet, mit OCR erfasst und mit PoCoTo nachkorrigiert. Durch die Verfügbarmachung unter Open Source Lizenzen sind die Barrieren damit so gering wie möglich gehalten und beschränken sich nur noch auf das notwendige technische Knowhow der Anwendung, für die wir ausführliche Dokumentationen erstellt haben.
Mit dem Fokus auf Latein als der historisch dominierenden Drucksprache sowie Altgriechisch hoffen wir insbesondere auch der Community der F-AG 4 ein nützliches Werkzeug verschafft zu haben.
Fortschritte auf dem Gebiet des Auftrags bei anderen Stellen
Uns ist keine andere Gruppe bekannt, die sich mit dem Problem der interaktiven Nachkorrektur historischer OCR-erfasster Texte mit eigenen Toolentwicklungen beschäftigt. Jedoch fand ein intensiver Austausch mit der Gruppe von Greg Crane an der Universität Leipzig statt, wo Ben Kiessling mit seiner Nidaba-Pipeline (siehe auch die Nidaba Dokumentation) die Teilprobleme der Erzeugung von OCR-Resultaten mit eingebetteten Bildkoordinaten für verschiedene Formate (hOCR, ABBYY XML, TEI, Alto) und die Open-Source-Engines Tesseract und OCRopus ebenfalls behandelt hat. Die Entwicklung ist aufeinander abgestimmt, so dass jetzt mit Nidaba eine weitere Implementierung von für PoCoTo geeigneten Input-Formaten (ABBYY XML und hOCR generiert durch Tesseract und OCRopus) vorliegt.
Stand der CLARIN-Integration
Der Profiler-Server wurde vom CLARIN-D-Zentrum in Leipzig (Prof. Heyer) in Betrieb genommen und stellt derzeit die Fehlerprofilierung für die folgenden Sprachen zur Verfügung: Deutsch (modern und historisch), Latein und Altgriechisch.
Zusätzlich und unabhängig von dieser öffentlichen Profiler-Instanz kann man sich aus den auf Github verfügbaren Quellen aber auch eine eigene private Instanz aufsetzen und mit Sprachressourcen nach eigenem Gusto (soweit verfügbar) bestücken. Im PoCoTo-Client ist dann lediglich darauf zu achten, dass die URL zu diesem Profiler eingetragen ist (siehe Handbuch).
Erfolgte / geplante Veröffentlichungen
Uwe Springmann & Florian Fink (2016). CIS OCR Workshop v1.0: OCR and postcorrection of early printings for digital humanities. Zenodo. 10.5281/zenodo.46571 ![]()
Es ist geplant, den jetzt erreichten Stand des Nachkorrekturtools als Bericht mit einem Fokus auf der Nachkorrektur von lateinischen und altgriechischen OCR-erfassten Texten bei der im Herbst 2016 stattfindenden Conference on Digital Access to Textual Cultural Heritage (DATeCH) einzureichen.